HTTP - The Guts of WWW
Networking ArchiveThe Internet is such a broad term, it can mean so many things, within the Internet we have email, newsgroups, bit torrent, online gaming etc, but this article focuses on the part you probably know best: The World Wide Web.
Although the ‘World Wide Web (WWW)’ sounds like yet another term for the Internet, it’s actually not. It’s describing a specific aspect of the web, the process of viewing content remotely using the HTTP protocol.
This article goes under the cover of the Word Wide Web and into the protocol that brings us Facebook, Google and eBay - HTTP - the Hypertext Transfer Protocol. I warn you it’s not a light read (easier then the RFC though!) but such a subject has a diverse history, and the technology has constantly had to adapt to a new world of online users. If you’re interested in how Facebook’s Webpage’s get to your computer - then this guide is for you.
Defining the Standard
The HTTP protocol has been widely accredited to one person - Tim Berners-Lee. Tim began work on HTTP back in 1990 when the need for a much easier way to distribute information between computers became obvious. While working at CERN, he wrote the first ever web server and web browser, starting the revolution we now know as URL’s, HTML and WWW. Once the technology matured, Tim wrote the first official RFC for two versions of his new protocol - RFC1945 - Hypertext Transfer Protocol – HTTP/1.0.
Note
The first ever version of HTTP was actually HTTP/0.9 created around 1990 by Tim Berners-Lee. It was extremely basic and didn't serve much use outside of the CERN lab - but because it paved the way for HTTP/1.0, Berners-Lee included it in the first official RFC. HTTP/1.0 defined the protocol. Simply put - other people could now create applications to interact with HTTP, and that's exactly what happened. Companies like Netscape popped up and Microsoft took an interest with their 'Internet Explorer' add-on to Windows 95, and before you knew it - the world was talking HTTP. The protocol was defined in 1996 - at least a year after the first commercial browser came out. This goes to show the protocol was an instant success long before the inventors could even document it - an event that happens much throughout IT history (wireless for example!).HTTP/1.0 enjoyed a good run from 1996 until 1999. Even after 1999 it continued to be used by many servers and browsers, and is still a large percentage of Internet traffic to this day. But in June 1999, HTTP/1.1 was defined by Berners-Lee and many other talented people from around the globe. Known as RFC2616 - HTTP/1.1 contained much needed improvements and enhancements over HTTP/1.0, in fact- there wasn’t much to document because many commercial products, struggling to keep up with the demand for new features - added their own technologies which became unofficially known as HTTP/1.0+.
Today we mostly use HTTP/1.1 with a little HTTP/1.0 for some devices. All modern browsers understand both protocols, but try to use the latest if possible. HTTP/1.0 still lingers around because of some proxy servers and gateways that exist on the Internet even today, however there’s little between them that causes problems for your average modern Internet user.
HTTP In a Nutshell
Regardless of the protocol version and its intricacies, HTTP was designed to do one thing: retrieve remote documents. Although that’s a gross oversimplification, it is the main purpose of HTTP today. We use it every time we view a web page, fill in an online form or search the Internet.
Web pages are simply files made up of objects. For example, this page is a page containing text and pictures. The file itself is an object, and each image is an object. They are all stored on a server just like data is stored on your PC. In order for you to view them, your computer has to download these objects from the server, and display them on your screen. HTTP facilitates this process. Your browser constructs the necessary HTTP request message, sends it to the server containing this page (found using the URL you enter, or by following the information in a link\button), then sends that HTTP request to the server. If everything goes well, the server sends a HTTP response - including the files (objects) you asked for.
Finally your browser saves them into the Internet cache on your computer, and displays them. Simple ha?
The diagram below shows a typical HTTP connection between a client and server, I’ve also included some of the basic TCP settings such as port number to highlight how HTTP relies on the transport layer underneath to handle the specifics of data transfer.

Of course things will always get more complicated. Many modern web pages are made up of several objects, so HTTP has to fetch dozens of objects, each one requiring a request\response message, and each one needing to travel between the server and your computer. HTTP makes easy work of this thanks to being lightweight and using simple text based headers, even though it’s capable of transferring binary data.
Before moving on, it’s worth noting the main differences between HTTP/1.0 and HTTP/1.1. The main jump was the introduction of persistent connections. HTTP/1.0 had to create a new connection for every single object on a web page. This wasn’t so much of an issue when a web page consisted of mostly text and the odd image, but you couldn’t realistically download Amazon’s homepage in any kind of decent time frame using HTTP/1.0. HTTP/1.1 allows clients and servers to reuse the same TCP connection to transfer multiple objects, thanks to the Connection header.
Not only did persistent connections come into effect, but HTTP/1.1 introduced improved cache handling, compression of data during transfer, error handling and proxy authentication. All features that we rely on today. HTTP/1.1 is the most widely used version of HTTP even today.
How did HTML get involved with HTTP?
Tim Berners-Lee created the very first HTML language by basing it on the then popular SGML (Standard Generalized Markup Language). It was used to tell clients how to display the data, while HTTP simply transferred it. HTML quickly became an open standard, with many scientists and academics around the world contributing to its success. In fact, you can even find the early discussion on the net today, an example can be found here, where a discussion for the now valuable image tag was born.HTTP is very much a web standard now, and is still being developed. You can find the latest discussions (as of 2008) here.
Detailed Look at HTTP
Probably the best way to see how HTTP works is to see it in action, in this section; we’ll take a look at a very basic - yet valid HTTP conversation between a Windows Internet Explorer client and Microsoft’s IIS server. We’ll transfer a single HTML page, only containing text, and then increase the complexity to show exactly how HTTP handles this content.
To start with, let’s perform a simple connection between the client and server; it’s as simple as going to the servers root URL. Below is a simple diagram, along with the conversation HTTP headers:
Client request:
GET / HTTP/1.1
User-Agent: Opera/9.26 (Windows NT 5.1; U; en)
Host: 192.168.1.10
Accept: text/html
Cache-Control: no-cache
Connection: Keep-Alive
Server Response:
HTTP/1.1 200 OK
Content-Length: 998
Content-Type: text/html
Server: Microsoft-IIS/6.0
Date: Sun, 8 Jun 2008 20:01:10 GMT
<html>
<head><title>this is a test</title>
(...)
The actual HTTP headers are in bold, and their values are listed to the right. We start with a client request. The first line is the actual request, asking the server to ‘get’ the file test.txt using the HTTP/1.1 protocol. The request is sent to the server located in the ‘Host’ header (couple the host header to the relative filename in the request and you have a URL). The other headers vary from system to system, though the ones you see here are the most common. Here’s a brief description of HTTP/1.1’s most common headers:
| Header Name | Purpose | Request\Response |
|---|---|---|
| Accept | Informs the server what media types the client can handle | Request |
| User-Agent | Contains information about the requesting client, for informational or tracking purposes only | Request |
| Host | The host machine to which the request is intended | Request |
| Content-Length | The length of the response, used to alert clients that data is available | Request & Response |
| Content-Type | Contains information about the requesting client, for informational or tracking purposes only | Response |
| Last-Modified | The date and time the server believes the file was last modified | Response |
| Server | The server name and possibly version | Response |
| Date | The date at which the response was sent | Response |
| If-Modified-Since | If the object requested hasn't been modified since this date, the server will return a 304 code and that's it. However if the object is newer then the date in the request, the server processes it as usual | Request |
| Connection | Specify the type of connection between two endpoints, used to signal a connection should be kept open or closed | Request & Response |
A full list of HTTP header explanation can be found in the HTTP/1.1 RFC located here.
There are many more headers which HTTP can use during normal request\responses - Authorization, caching and data formatting to name a few; however these are the most common that you would expect to see on modern web servers\browsers.
With every request that HTTP sends, a response code is returned (assuming the server received the request!), HTTP response codes are grouped into 5 sets of numbers:
1xx - Provisional codes: used to inform the client of single-lined informational message 2xx - used to signal a successful request that the server can process. Common 2xx messages are 200 OK and 202 Accepted 3xx - Redirection codes - used to inform the client that further action is required such as following a temporary URL. The response generally includes the new location of the file. Examples are 301 Move permanently and 304 not modified. 4xx - Indicates something was wrong with the client request. The most common being 404 not found, meaning the client requested an object or file that doesn’t exist. Others include 401 unauthorized and 403 forbidden. 5xx - indicates the server did something wrong, common errors are 500 internal server error (usually occurs when permissions or configurations are incorrect for the web server to access resources) and 503 service unavailable meaning something has interrupted the HTTP session.
Modern browsers are configured to read these response codes and give friendly errors accordingly.
HTTP/1.1 was also tweaked to include enhancements for intermediate devices. After all, today it’s becoming less and less likely that you’re actually talking to the web server directly as networks become more secure and efficient.
Proxy servers and caching engines have always suffered the hardships of interpreting data as it traverses the network. HTTP/1.1 allows content to be marked as cacheable, non-cacheable and also configures more accurate document expiration as we’ll briefly look at in the next section.
Cacheable content
Towards the end of the 90’s, HTTP had realized the need to support much more then just clients and servers. HTTP transactions needed far more granular control, and with more and more clients requesting content from the same servers, bottlenecks appeared, causing slow responses.
The solution came in the form of Proxy Servers (or cache content servers, web caches etc). They basically acted as ‘proxies’ between the server and client, storing commonly requested content for whichever clients were configured to use them. Many large companies that wanted to reduce the amount of outgoing HTTP requests would install proxy servers to further control the flow of traffic.
Note
A web cache\cache content server\proxy server all basically performs the same task. When a request arrives at a caching device, it checks to see if a 'local' copy is available. If it is, it will serve the client its local copy instead of requesting it from the server. However processes have to be in place to ensure the cache is supplying the client with the most up to date objects.HTTP/1.0 had virtually no cache control apart from the ‘If-Modified-Since’ header, which allowed for basic checking of newly updated content. HTTP/1.1 addressed these shortcomings with an array of new headers. Though If-Modified-Since is still very much one of the main (and simplest) ways a caching device can check.
If-Modified-Since works by sending a request to the server once a browser realizes that it already has a local copy stored in its cache. All modern browsers have local cache stores (or temporary internet files as Internet Explorer calls it), and instead of requesting a page from the server, it will use its local copy. But before it can do this - the browser must check the local copy is ‘fresh’ enough. It does this by sending an If-Modified-Since header.
The If-Modified-Since header has a value of the Last-Modified date that was originally sent in the server response when the object was first requested. If the Last-Modified date on the server is not any newer then the client has, the server returns a 304 Not Modified header with no content, and the cache (or browser) knows it can safely serve its own copy.
Sounds complicated to start with, but it really is just comparing dates. Things get more confusing when you use other methods HTTP/1.1 introduced to resolve several issues. For more information on advanced caching methods, I’d highly recommend the book HTTP: The definitive guide by David Gourley and Brian Totty.
HTTP Transport
HTTP has come along way from the days of retrieving a document in plain text. When the need for secure connections arose, HTTP had to once again adjust to meet the growing needs of the internet population.
HTTP in itself does not provide any security other then basic authentication, and even this does not actually protect the data from being stolen or manipulated on the wire. HTTP did have one advantage over others… it makes a great transport protocol. Sometime between HTTP/1.0+ and HTTP/1.1, the CONNECT method was added to HTTP. CONNECT allows HTTP to instruct intermediate devices to connect to resources using different ports and protocols. This came in handy because clients configured to use proxies had no choice about which port\server they connect to.
To see the problem, let’s take a look at a typical connection to a secure site without a proxy:
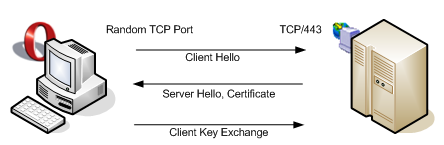
The client initiates a connection on port 443 using TCP. They then exchange data using a negotiated version of SSL or TLS - nothing to do with HTTP so far.
However if the client uses a proxy - the connection to 443 will most likely get rejected (unless the proxy is explicitly listening on port 443). Browsers get around this issue by changing their behavior depending if they are configured to use a proxy or not. The following diagram shows what the same request above looks like when the browser is configured to use a proxy:
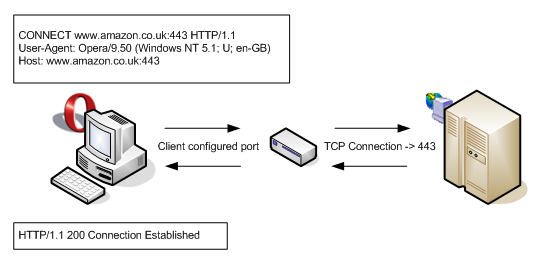
The browser knows it’s trying to connect to a HTTPS site (note the schema in the URL), and it also knows it’s configured to go via a proxy, therefore it sends a HTTP CONNECT request over the HTTP port configured instead of creating a connection on port 443 (SSL). Proxies must know how to interpret HTTP CONNECT methods, and a decent implementation will create an SSL connection to the server, relaying the encrypted messages back to the client using HTTP (in fact, decent proxies will create two connections, one to the server and one to the client, so HTTPS is maintained throughout the entire path of the data).
SSL is just one example of a protocol being tunneled over HTTP. Many other protocols can be used, such as XML and WebDev.
Conclusion
HTTP is probably the most dynamic, robust protocol that’s in use today, it’s had to evolve constantly to adapt to the ever increasing demands of the web, and with HTTP/2.0 round the corner (actually it’s been in development since 1997!), it’s only going to get more and more functional.
For more information, you can view the RFC’s (Request for Comments). These documents are the manuals that define the protocol, and although they are a very heavy read, they will explain absolutely everything.
Hypertext Transfer Protocol – HTTP/1.0 - Main RFC for HTTP/1.0, also covers HTTP/0.9
http://www.ietf.org/rfc/rfc1945.txt
Hypertext Transfer Protocol – HTTP/1.1 - Main RFC for HTTP/1.1
http://www.w3.org/Protocols/rfc2616/rfc2616.html
